
![O:28:"craft\elements\db\AssetQuery":96:{s:27:"�yii\base\Component�_events";a:0:{}s:35:"�yii\base\Component�_eventWildcards";a:0:{}s:30:"�yii\base\Component�_behaviors";a:1:{s:12:"customFields";O:35:"craft\behaviors\CustomFieldBehavior":112:{s:5:"owner";r:1;s:34:"�yii\base\Behavior�_attachedEvents";a:0:{}s:10:"hasMethods";b:1;s:16:"canSetProperties";b:1;s:15:"personFirstName";N;s:14:"personLastName";N;s:5:"image";N;s:11:"personTitle";N;s:14:"contentBuilder";N;s:4:"text";N;s:11:"attribution";N;s:6:"people";N;s:10:"groupTitle";N;s:13:"relatedPeople";N;s:15:"relatedProjects";N;s:11:"relatedNews";N;s:8:"heroText";N;s:6:"teaser";N;s:13:"featuredImage";N;s:11:"postContent";N;s:6:"alumni";N;s:4:"logo";N;s:7:"website";N;s:11:"affiliation";N;s:7:"project";N;s:15:"applicationLink";N;s:16:"shortDescription";N;s:19:"applicationDeadline";N;s:10:"employment";N;s:15:"nonprofitStatus";N;s:13:"callsToAction";N;s:11:"description";N;s:7:"endDate";N;s:7:"endTime";N;s:14:"relatedProgram";N;s:9:"startDate";N;s:9:"startTime";N;s:8:"ctaTitle";N;s:7:"ctaLink";N;s:14:"ctaDescription";N;s:8:"timeZone";N;s:4:"tags";N;s:7:"context";N;s:11:"peopleGroup";N;s:9:"groupName";N;s:5:"users";N;s:4:"body";N;s:6:"header";N;s:7:"buttons";N;s:10:"buttonLink";N;s:5:"style";N;s:14:"quickLinkItems";N;s:8:"itemLink";N;s:15:"quickLinksTitle";N;s:17:"quickLinksDisplay";N;s:10:"visibility";N;s:9:"linkField";N;s:13:"featuredEvent";N;s:12:"featuredPost";N;s:12:"contributors";N;s:11:"grantAmount";N;s:8:"richText";N;s:3:"bio";N;s:4:"news";N;s:8:"projects";N;s:4:"jobs";N;s:6:"events";N;s:9:"resources";N;s:7:"caption";N;s:14:"mailingAddress";N;s:7:"twitter";N;s:12:"contactEmail";N;s:3:"ein";N;s:7:"userOrg";N;s:9:"loginText";N;s:8:"grantees";N;s:10:"fileGroups";N;s:18:"sectionDescription";N;s:12:"sectionTitle";N;s:5:"files";N;s:5:"width";N;s:12:"resourceType";N;s:12:"accessDenied";N;s:8:"noAccess";N;s:8:"linkedin";N;s:6:"github";N;s:17:"incubatorProjects";N;s:9:"listItems";N;s:14:"sectionContent";N;s:13:"headerContent";N;s:4:"year";N;s:13:"passwordReset";N;s:19:"restrictedResources";N;s:11:"headerStyle";N;s:5:"embed";N;s:14:"seoDescription";N;s:8:"seoImage";N;s:14:"analyticsEmbed";N;s:17:"programLogoSquare";N;s:19:"newsletterEmbedCode";N;s:11:"seoSettings";N;s:9:"shareLink";N;s:12:"feedbackLink";N;s:15:"feedbackFormUrl";N;s:26:"resourceFeedbackButtonText";N;s:16:"noUpcomingEvents";N;s:14:"personPronouns";N;s:17:"expiredJobWarning";N;s:10:"eventStart";N;s:8:"eventEnd";N;s:11:"maintainers";N;s:55:"�craft\behaviors\CustomFieldBehavior�_customFieldValues";a:0:{}}}s:6:"select";a:1:{s:2:"**";s:2:"**";}s:12:"selectOption";N;s:8:"distinct";b:0;s:4:"from";N;s:7:"groupBy";N;s:4:"join";a:1:{i:0;a:3:{i:0;s:10:"INNER JOIN";i:1;a:1:{s:9:"relations";s:14:"{{%relations}}";}i:2;a:4:{i:0;s:3:"and";i:1;s:40:"[[relations.targetId]] = [[elements.id]]";i:2;a:2:{s:18:"relations.sourceId";i:860;s:17:"relations.fieldId";i:3;}i:3;a:3:{i:0;s:2:"or";i:1;a:1:{s:22:"relations.sourceSiteId";N;}i:2;a:1:{s:22:"relations.sourceSiteId";i:1;}}}}}s:6:"having";N;s:5:"union";N;s:11:"withQueries";N;s:6:"params";a:0:{}s:18:"queryCacheDuration";N;s:20:"queryCacheDependency";N;s:5:"where";N;s:5:"limit";N;s:6:"offset";N;s:7:"orderBy";a:1:{s:19:"relations.sortOrder";i:4;}s:7:"indexBy";N;s:16:"emulateExecution";b:0;s:11:"elementType";s:20:"craft\elements\Asset";s:5:"query";N;s:8:"subQuery";N;s:12:"contentTable";s:12:"{{%content}}";s:12:"customFields";N;s:9:"inReverse";b:0;s:7:"asArray";b:0;s:18:"ignorePlaceholders";b:0;s:6:"drafts";b:0;s:17:"provisionalDrafts";b:0;s:7:"draftId";N;s:7:"draftOf";N;s:12:"draftCreator";N;s:15:"savedDraftsOnly";b:0;s:9:"revisions";b:0;s:10:"revisionId";N;s:10:"revisionOf";N;s:15:"revisionCreator";N;s:2:"id";N;s:3:"uid";N;s:14:"siteSettingsId";N;s:10:"fixedOrder";b:0;s:6:"status";a:1:{i:0;s:7:"enabled";}s:8:"archived";b:0;s:7:"trashed";b:0;s:11:"dateCreated";N;s:11:"dateUpdated";N;s:6:"siteId";i:2;s:6:"unique";b:0;s:11:"preferSites";N;s:6:"leaves";b:0;s:9:"relatedTo";N;s:5:"title";N;s:4:"slug";N;s:3:"uri";N;s:6:"search";N;s:3:"ref";N;s:4:"with";N;s:13:"withStructure";N;s:11:"structureId";N;s:5:"level";N;s:14:"hasDescendants";N;s:10:"ancestorOf";N;s:12:"ancestorDist";N;s:12:"descendantOf";N;s:14:"descendantDist";N;s:9:"siblingOf";N;s:13:"prevSiblingOf";N;s:13:"nextSiblingOf";N;s:16:"positionedBefore";N;s:15:"positionedAfter";N;s:17:"�*�defaultOrderBy";a:1:{s:20:"elements.dateCreated";i:3;}s:53:"�craft\elements\db\ElementQuery�_placeholderCondition";N;s:51:"�craft\elements\db\ElementQuery�_placeholderSiteIds";N;s:39:"�craft\elements\db\ElementQuery�_result";N;s:47:"�craft\elements\db\ElementQuery�_resultCriteria";N;s:46:"�craft\elements\db\ElementQuery�_searchResults";N;s:42:"�craft\elements\db\ElementQuery�_cacheTags";N;s:42:"�craft\elements\db\ElementQuery�_columnMap";a:0:{}s:51:"�craft\elements\db\ElementQuery�_joinedElementTable";b:0;s:8:"editable";N;s:7:"savable";N;s:8:"volumeId";N;s:8:"folderId";N;s:10:"uploaderId";N;s:8:"filename";N;s:4:"kind";N;s:6:"hasAlt";b:1;s:5:"width";N;s:6:"height";N;s:4:"size";N;s:12:"dateModified";N;s:17:"includeSubfolders";b:0;s:10:"folderPath";N;s:14:"withTransforms";N;}](https://images.codeforsociety.org/production/images/People/Angela-Okune-bio-photo.jpeg?w=360&h=360&auto=compress%2Cformat&fit=crop&dm=1671227256&s=90cfc0c695f5ff0486c2a6df0c070cc9)
![O:28:"craft\elements\db\AssetQuery":96:{s:27:"�yii\base\Component�_events";a:0:{}s:35:"�yii\base\Component�_eventWildcards";a:0:{}s:30:"�yii\base\Component�_behaviors";a:1:{s:12:"customFields";O:35:"craft\behaviors\CustomFieldBehavior":112:{s:5:"owner";r:1;s:34:"�yii\base\Behavior�_attachedEvents";a:0:{}s:10:"hasMethods";b:1;s:16:"canSetProperties";b:1;s:15:"personFirstName";N;s:14:"personLastName";N;s:5:"image";N;s:11:"personTitle";N;s:14:"contentBuilder";N;s:4:"text";N;s:11:"attribution";N;s:6:"people";N;s:10:"groupTitle";N;s:13:"relatedPeople";N;s:15:"relatedProjects";N;s:11:"relatedNews";N;s:8:"heroText";N;s:6:"teaser";N;s:13:"featuredImage";N;s:11:"postContent";N;s:6:"alumni";N;s:4:"logo";N;s:7:"website";N;s:11:"affiliation";N;s:7:"project";N;s:15:"applicationLink";N;s:16:"shortDescription";N;s:19:"applicationDeadline";N;s:10:"employment";N;s:15:"nonprofitStatus";N;s:13:"callsToAction";N;s:11:"description";N;s:7:"endDate";N;s:7:"endTime";N;s:14:"relatedProgram";N;s:9:"startDate";N;s:9:"startTime";N;s:8:"ctaTitle";N;s:7:"ctaLink";N;s:14:"ctaDescription";N;s:8:"timeZone";N;s:4:"tags";N;s:7:"context";N;s:11:"peopleGroup";N;s:9:"groupName";N;s:5:"users";N;s:4:"body";N;s:6:"header";N;s:7:"buttons";N;s:10:"buttonLink";N;s:5:"style";N;s:14:"quickLinkItems";N;s:8:"itemLink";N;s:15:"quickLinksTitle";N;s:17:"quickLinksDisplay";N;s:10:"visibility";N;s:9:"linkField";N;s:13:"featuredEvent";N;s:12:"featuredPost";N;s:12:"contributors";N;s:11:"grantAmount";N;s:8:"richText";N;s:3:"bio";N;s:4:"news";N;s:8:"projects";N;s:4:"jobs";N;s:6:"events";N;s:9:"resources";N;s:7:"caption";N;s:14:"mailingAddress";N;s:7:"twitter";N;s:12:"contactEmail";N;s:3:"ein";N;s:7:"userOrg";N;s:9:"loginText";N;s:8:"grantees";N;s:10:"fileGroups";N;s:18:"sectionDescription";N;s:12:"sectionTitle";N;s:5:"files";N;s:5:"width";N;s:12:"resourceType";N;s:12:"accessDenied";N;s:8:"noAccess";N;s:8:"linkedin";N;s:6:"github";N;s:17:"incubatorProjects";N;s:9:"listItems";N;s:14:"sectionContent";N;s:13:"headerContent";N;s:4:"year";N;s:13:"passwordReset";N;s:19:"restrictedResources";N;s:11:"headerStyle";N;s:5:"embed";N;s:14:"seoDescription";N;s:8:"seoImage";N;s:14:"analyticsEmbed";N;s:17:"programLogoSquare";N;s:19:"newsletterEmbedCode";N;s:11:"seoSettings";N;s:9:"shareLink";N;s:12:"feedbackLink";N;s:15:"feedbackFormUrl";N;s:26:"resourceFeedbackButtonText";N;s:16:"noUpcomingEvents";N;s:14:"personPronouns";N;s:17:"expiredJobWarning";N;s:10:"eventStart";N;s:8:"eventEnd";N;s:11:"maintainers";N;s:55:"�craft\behaviors\CustomFieldBehavior�_customFieldValues";a:0:{}}}s:6:"select";a:1:{s:2:"**";s:2:"**";}s:12:"selectOption";N;s:8:"distinct";b:0;s:4:"from";N;s:7:"groupBy";N;s:4:"join";a:1:{i:0;a:3:{i:0;s:10:"INNER JOIN";i:1;a:1:{s:9:"relations";s:14:"{{%relations}}";}i:2;a:4:{i:0;s:3:"and";i:1;s:40:"[[relations.targetId]] = [[elements.id]]";i:2;a:2:{s:18:"relations.sourceId";i:8968;s:17:"relations.fieldId";i:3;}i:3;a:3:{i:0;s:2:"or";i:1;a:1:{s:22:"relations.sourceSiteId";N;}i:2;a:1:{s:22:"relations.sourceSiteId";i:1;}}}}}s:6:"having";N;s:5:"union";N;s:11:"withQueries";N;s:6:"params";a:0:{}s:18:"queryCacheDuration";N;s:20:"queryCacheDependency";N;s:5:"where";N;s:5:"limit";N;s:6:"offset";N;s:7:"orderBy";a:1:{s:19:"relations.sortOrder";i:4;}s:7:"indexBy";N;s:16:"emulateExecution";b:0;s:11:"elementType";s:20:"craft\elements\Asset";s:5:"query";N;s:8:"subQuery";N;s:12:"contentTable";s:12:"{{%content}}";s:12:"customFields";N;s:9:"inReverse";b:0;s:7:"asArray";b:0;s:18:"ignorePlaceholders";b:0;s:6:"drafts";b:0;s:17:"provisionalDrafts";b:0;s:7:"draftId";N;s:7:"draftOf";N;s:12:"draftCreator";N;s:15:"savedDraftsOnly";b:0;s:9:"revisions";b:0;s:10:"revisionId";N;s:10:"revisionOf";N;s:15:"revisionCreator";N;s:2:"id";N;s:3:"uid";N;s:14:"siteSettingsId";N;s:10:"fixedOrder";b:0;s:6:"status";a:1:{i:0;s:7:"enabled";}s:8:"archived";b:0;s:7:"trashed";b:0;s:11:"dateCreated";N;s:11:"dateUpdated";N;s:6:"siteId";i:2;s:6:"unique";b:0;s:11:"preferSites";N;s:6:"leaves";b:0;s:9:"relatedTo";N;s:5:"title";N;s:4:"slug";N;s:3:"uri";N;s:6:"search";N;s:3:"ref";N;s:4:"with";N;s:13:"withStructure";N;s:11:"structureId";N;s:5:"level";N;s:14:"hasDescendants";N;s:10:"ancestorOf";N;s:12:"ancestorDist";N;s:12:"descendantOf";N;s:14:"descendantDist";N;s:9:"siblingOf";N;s:13:"prevSiblingOf";N;s:13:"nextSiblingOf";N;s:16:"positionedBefore";N;s:15:"positionedAfter";N;s:17:"�*�defaultOrderBy";a:1:{s:20:"elements.dateCreated";i:3;}s:53:"�craft\elements\db\ElementQuery�_placeholderCondition";N;s:51:"�craft\elements\db\ElementQuery�_placeholderSiteIds";N;s:39:"�craft\elements\db\ElementQuery�_result";N;s:47:"�craft\elements\db\ElementQuery�_resultCriteria";N;s:46:"�craft\elements\db\ElementQuery�_searchResults";N;s:42:"�craft\elements\db\ElementQuery�_cacheTags";N;s:42:"�craft\elements\db\ElementQuery�_columnMap";a:0:{}s:51:"�craft\elements\db\ElementQuery�_joinedElementTable";b:0;s:8:"editable";N;s:7:"savable";N;s:8:"volumeId";N;s:8:"folderId";N;s:10:"uploaderId";N;s:8:"filename";N;s:4:"kind";N;s:6:"hasAlt";b:1;s:5:"width";N;s:6:"height";N;s:4:"size";N;s:12:"dateModified";N;s:17:"includeSubfolders";b:0;s:10:"folderPath";N;s:14:"withTransforms";N;}](https://images.codeforsociety.org/production/images/AC.jpeg?w=360&h=360&auto=compress%2Cformat&fit=crop&dm=1671227314&s=f57cd856aa0fda37afba2e012c212167)
Supported by the Code for Science & Society Event Fund (Gordon and Betty Moore Foundation Grant GBMF8449), Data Umbrella has been hosting regular data sprints to grow the skills and confidence of first-time and regular contributors to open source software communities such as scikit-learn, a widely used machine learning library of Python. In this post–part of an ongoing series that focuses on the organizing processes, tools, and practices used to run successful Event Fund-sponsored Open Science events–we learn about some of the changes that Data Umbrella incorporated when shifting from in-person data sprints to an online format. Through this blog series, Event Fund seeks to highlight the processes and practices that undergird more inclusive and accessible data science event programming.
Prior to 2020, most data sprints were held in person during intensive 8-hour-long days. Data Umbrella founder, Reshama Shaikh, for example, led several in-person sprints in New York (2017, 2018, 2019), Nairobi (2019) and San Francisco (2019). Data Umbrella had always been interested in developing online resources and exploring ways to enable virtual participation, but this was not able to become a priority until 2020 when the pandemic forced everything online including data sprints. It was clear that an 8-hour in-person event could not just switch to being an 8-hour online event. So the move to online data sprints required the team to rethink the format and mechanisms of the event.
Data Umbrella reduced the synchronous time into multiple shorter events including pre-sprint office hours and post-sprint office hours and a four hour sprint. To enable participants to get to know each other in the virtual setting, their photos and location were shared on the sprint websites on an opt-in basis. A greater emphasis was put on pair programming, an aspect that was highly referenced in the feedback survey as one of most appreciated aspects of the online data sprints.
A pilot sprint was run after the pandemic began, in June 2020, to explore what running a data sprint online might look like. After a successful pilot attended by almost 40 participants from around the world, Data Umbrella, with support from the Event Fund, was able to organize three online open source sprints in 2021 (February 2021; June 2021; October 2021) with over 100 participants attending from around the world.
Summary of Online Sprint Events
Event | Website / Report | Event Dates | Participants |
Global Sprint (Pilot online sprint) | [a] None [b] 06-Jun-2020 [c] 20-Jun-2020 | [a] N/A [b] 42 [c] 6 | |
Africa and Middle East Sprint | [a] 30-Jan-2021 [c] 20-Feb-2021 | [a] 15 [c] 7 | |
Latin American Sprint | [a] 19-Jun-2021 [c] 10-Jul-2021 | [a] 29 [c] 12 | |
Africa & Middle East Sprint | [a] 16-Oct-2021 [c] 06-Nov-2021 | [a] 9 [c] 7 |
Sociotechnical infrastructure
In order to successfully run the online data sprint events, visible (technology software) and less visible infrastructures (norms, working styles) were important. For example:
- Pre- and Post-Sprint Office Hours: In order to help begin to build relationships amongst participants, Data Umbrella organized a one-hour office hour prior to and after the sprint. These meetings were an informal way for participants to ask any questions before the “official” event and to help set expectations around pair programming and what sort of “issues” in the GitHub repository they would work on. These office hours were hosted by Data Umbrella with attendance by the open source library maintainers and so, in a small group setting, community contributors and open source maintainers were able to better get to know each other, share their screens and walk through pull requests together. Such relaxed discussion spaces helped to strengthen the interpersonal relations necessary for open source libraries to be maintained.
- Sprint Preparation Checklist: Data Umbrella provided a Sprint Prep Checklist with a helpful list of resources to read and review prior to the online sprint, at their convenience. This allowed contributors flexibility in doing preparation work and to maximize the sprint time and experience with the library maintainers and their pair programming partners.
- Video Content with Transcripts: Data Umbrella organizers collaborated with the open source library maintainer to create videos (15-30 minutes in duration) which sprint participants could view at their convenience prior to the sprint. Transcripts were also created so that referencing videos was more easily accessible.
- Translations: Translations of the video transcripts and sprint website were done by volunteer community members for the Latin America sprint. The content was translated into Spanish and Portuguese. Translators were available at all three events (pre-sprint, sprint, post-sprint) to facilitate communication.
- Pair Programming: Sprint participants were assigned pair programming partners. The Data Umbrella organizing team matched as best they could based on time zones and experience (for example, matching first-time contributors with returning contributors).
- Repeat Sprints: For first-time contributors, the sprints are valuable and impactful in getting folks started with open source. The curve to contributing is still steep, particularly for a library such as scikit-learn. Repeated sprint events helped build confidence, experience, coding skills and new mentors, to name a few favorable outcomes.
- Curated “Issues” on GitHub: One of the barriers to new or continuing contributors in open source is having issues in GitHub with well-defined background information and steps to contributing. Data Umbrella has worked with the open source library maintainers to improve documentation on issues so contributors have coding issues they can continue to contribute to after the sprint.
Reaching new audiences
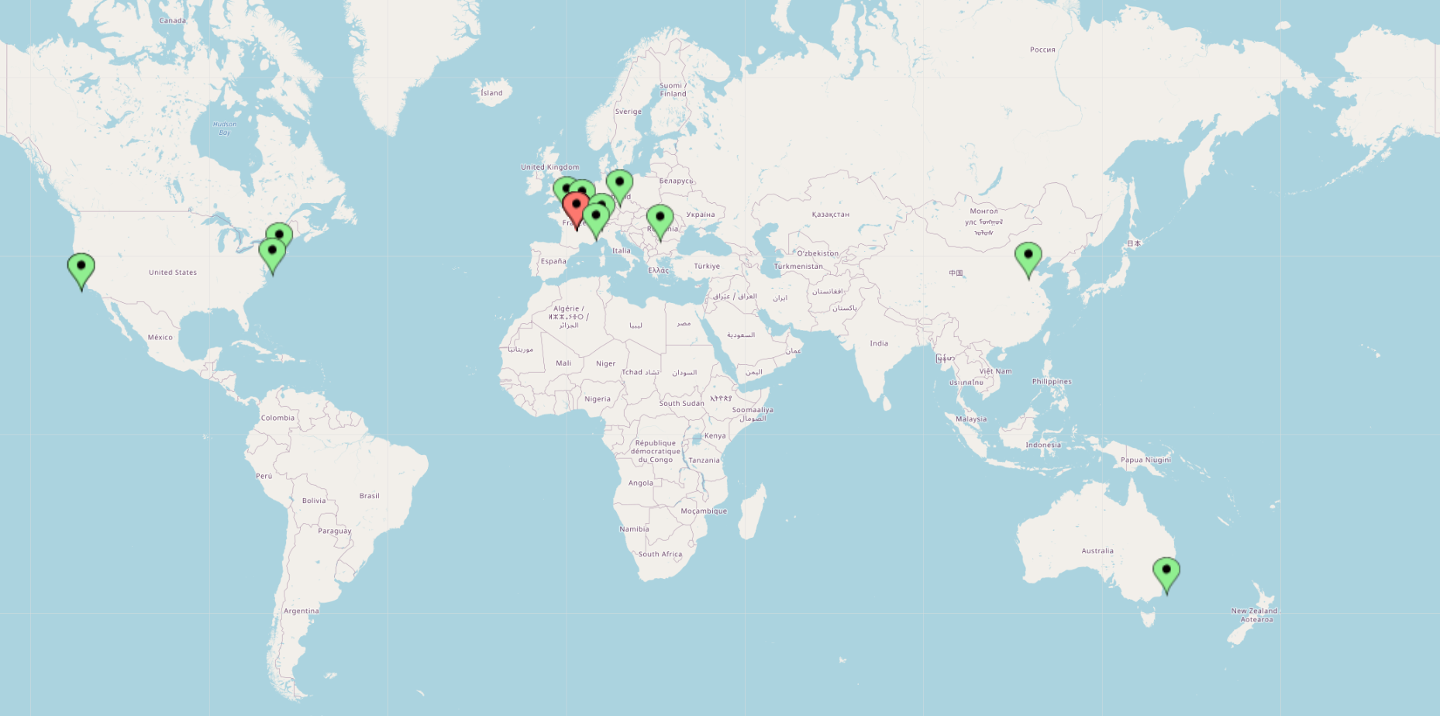
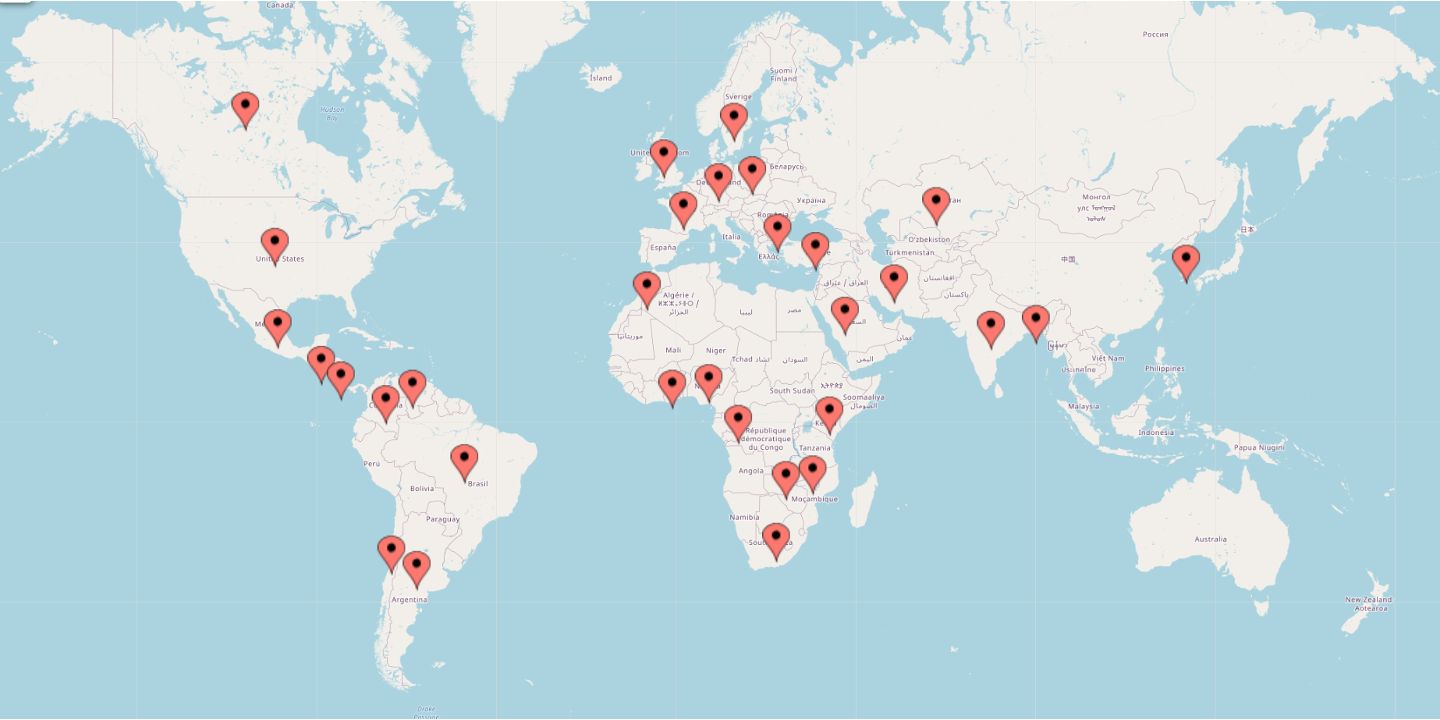
Data Umbrella began in 2019 to create a community for underrepresented persons in data science, expanding from a focus on increasing representation of women in open source communities towards more intersectional understandings of the diversity of open source software contributors. Figure 2 is a world map showing the locations of Data Umbrella’s 2021 sprint participants who joined from about 30 different countries. This map is particularly stark in contrast to Figure 1, the map of the founding team members of the software.
In running these sprints, Data Umbrella learned that documentation (text) about how to contribute can often be intimidating or inaccessible and that often other mediums (videos, transcripts, translations) help to make contributing more accessible. The Data Umbrella organizers also realized these sprints are not only important for contributors, they also provide an opportunity to the core development team to receive feedback on documentation and contributing process and to make improvements.
As a result of the data sprints, several exciting impact stories have begun to emerge. A returning sprint participant, Amanda D’Souza of India, worked on an issue related to a dataset which used ethically questionable data. She contributed to the numerous pull requests which moved this issue forward and removed the dataset from the library.
There are 1 million users of the scikit-learn library around the world. The core developer team is approximately 20 people and there are only 6 people on triage. A sprint participant from Latin America, Juan Martín Loyola, contributed extensively towards the scikit-learn library in 2021 as a result of the Data Umbrella sprints. He was recently invited to become a Triage Team member. Receiving this invitation is a significant milestone and one that Data Umbrella is very happy to have supported. Read more in “Interview with Juan Martín Loyola.”
Another contributor, Maren Westerman, was an attendee at all four Data Umbrella events and has now become an organizer for a meet-up group in her city in Germany. Maren is applying ideas she learned from the Data Umbrella sprints to organize her own meet-up and hackathon community.
A number of sprint participants wrote blogs on their sprint experience.
What’s next?
Data Umbrella event organizers would like to see growth in the community of contributors, especially with involvement from people outside of traditional metropolitan tech hubs in the US and Western Europe. In 2022 (Jan-Feb), Data Umbrella collaborated with PyMC (a Bayesian Python library) to create a series of videos and tutorials for the community on contributing to PyMC, which then culminated in an online sprint. Data Umbrella is organizing an open source sprint in June 2022 for the Python libraries NumPy and SciPy, with a focus on Africa and the Middle East. The group is looking for further funding to create resources that will enable others to run data sprints towards a “train-the-trainer” model.
Acknowledgements
Data Umbrella would like to thank the scikit-learn maintainers for their contributions to the sprints, from curating issues to patiently reviewing pull requests, updating the contributing documentation based on feedback and creating video resources.
Featured Image by David Clode on Unsplash